
The Hidden Engineering Tax of Using Document AI in Healthcare Products
Medical data extraction is quick. Making it reliable is where real value is built.
AI can read lab reports—but can it make them clinically usable at scale?


The Illusion of Structured Data
Artificial intelligence has made remarkable progress in reading medical documents. Modern document AI tools can now identify tables, recognize test names, and extract numerical values from lab reports with impressive accuracy. For many industries, that level of extraction would be enough.
In healthcare, it is only the beginning.
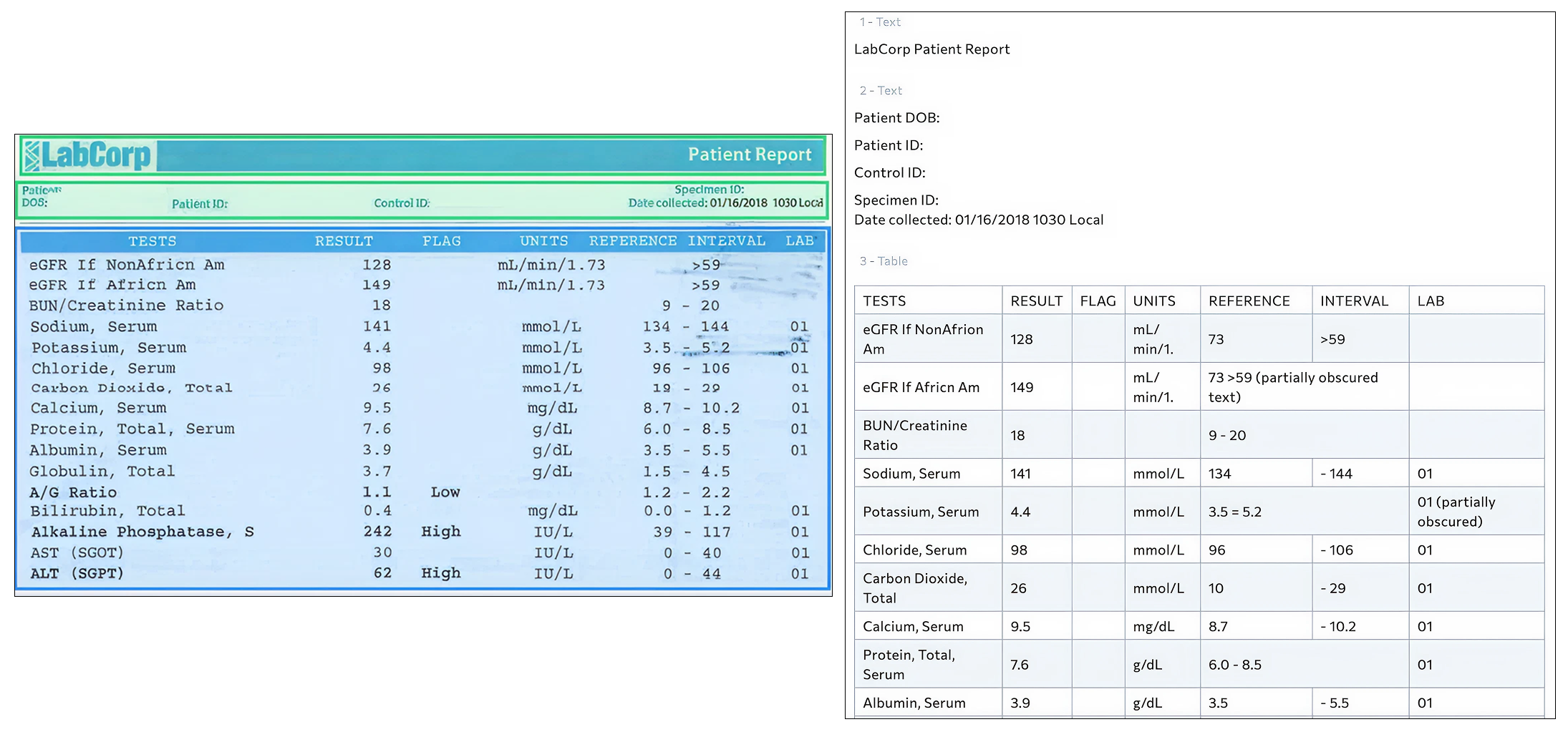
Recently, we evaluated a standard lab report using a document AI system to understand how well it could convert a real-world clinical document into structured data. In the image below, the original lab report is shown on the left, and the AI-generated structured output is shown on the right. At first glance, the result looks highly successful. The table structure is clear, the analyte names are visible, and the numeric test results appear to have been captured correctly. From a document processing perspective, this is a strong performance.
However, healthcare systems do not operate on visual structure alone. They rely on data that is standardized, comparable, and clinically reliable across different providers, labs, regions, and systems. That is where the real challenge begins.
When we examined the structured output more closely, several subtle but important issues emerged — the kinds of issues that are common in real-world clinical data extraction.
In some cases, clinical units were only partially captured. For example, a measurement that should be expressed with a standardized body surface area normalization may appear truncated in the output. While the number itself may be correct, the unit context is what makes the value clinically meaningful. Inconsistent or incomplete units make it difficult to compare results across labs or over time and can undermine both clinical interpretation and analytics.
We also observed problems with reference ranges, which are essential for determining whether a result is normal or abnormal. In the structured output, some reference ranges appeared fragmented or misread, with digits shifted or formatting disrupted. A small change in a reference range can alter how a system flags a result. This directly affects automated decision support, clinical alerts, and research analyses that depend on accurate categorization of results.
Another issue involved abnormality flags, such as indicators for high or low results. These markers were present in the original lab report but did not consistently carry through into the structured output. When these flags are missing or unreliable, downstream systems may fail to identify clinically significant findings, even when the raw numbers are present.
These discrepancies illustrate a broader truth in healthcare data: structured does not automatically mean usable.
Importantly, these challenges are not unique to any single tool. When we were building our own clinical data transformation product, we encountered many of the same issues. Converting lab and diagnostic reports into structured data is only the first step. Ensuring that units are complete and comparable, reference ranges are reliable, and abnormality indicators are preserved requires multiple layers of refinement and iteration. Solving for this reliably takes domain understanding, clinical context, and repeated real-world validation.
Why Structure Alone Is Not Enough
Document AI is highly effective at identifying where text and numbers appear on a page. Healthcare interoperability, however, depends on whether those numbers carry the same meaning everywhere they are used. That requires consistent units aligned with medical standards, validated and biologically plausible reference ranges, reliable identification of abnormal results, and mapping of tests to globally recognized terminologies such as LOINC.
The Reality: Healthcare Systems Do Not All Speak the Same Language
While global medical standards such as LOINC for lab tests, SNOMED CT for clinical terminology, and UCUM for units of measure provide a common clinical language, the reality inside healthcare systems is often more complex.
Many organizations and digital health platforms do not strictly adhere to these standards. They may rely on local codes, legacy test names, custom unit conventions, or internally defined reference ranges that have evolved over years of operational use. This is especially common in regional healthcare networks, long-standing laboratory systems, and rapidly growing digital health solutions that were built before interoperability standards became widely adopted.
As a result, real-world clinical data often exists in a hybrid state — partially aligned with global standards and partially shaped by local conventions. Any solution designed to make healthcare data usable at scale must be able to operate within this reality.
The goal is not to force every system into a single rigid model, but to create reliable mappings and harmonization across differing conventions so that data remains meaningful both within local systems and across broader healthcare ecosystems. In this sense, harmonization acts as a bridge between systems — enabling interoperability without requiring organizations to abandon the workflows and structures they already depend on.
Why This Matters at Scale
Without this additional layer of processing, data may look organized but still lack the consistency required for safe clinical workflows, meaningful analytics, and reliable AI training. When scaled across large populations or multi-site systems, small inconsistencies can compound into significant problems. Results may not be comparable across laboratories, automated rules may not trigger as intended, and machine learning models may learn patterns that reflect formatting artifacts rather than true clinical signals.
As healthcare becomes more data-driven, the quality and consistency of input data are becoming as important as the algorithms built on top of it. The promise of AI in healthcare does not depend only on smarter models. It depends on whether the underlying data has been made interoperable, standardized, and clinically coherent.
AI can read lab reports. Healthcare systems, however, require data that speaks a common clinical language. Achieving that level of understanding requires more than extraction. It requires harmonization.
What Buyers Should Look For When Evaluating Solutions
As healthcare organizations explore AI-powered document processing and interoperability solutions, it is important to understand that not all “structured data” is created equal.
When reviewing vendors or platforms that claim to extract lab data from PDFs and images, decision-makers should look beyond whether a table can be produced. The critical question is whether the data can be used safely and consistently within clinical systems, analytics platforms, and AI applications.
Key questions to consider include:
Without this deeper layer of clinical data harmonization, organizations risk integrating data that appears structured but behaves inconsistently in downstream systems. This can affect clinical workflows, research integrity, analytics accuracy, and the reliability of AI-driven tools.
The distinction between document extraction and clinical interoperability is becoming increasingly important as healthcare becomes more data-driven. Choosing the right partner means understanding not only how data is read, but how it is prepared for safe, standardized, and scalable use.
From Extraction to Interoperability
This is the category of problem Jonda Health focuses on solving. Through JondaX, we work on the layer that comes after document extraction — the stage where clinical diagnostic data must be standardized, validated, and aligned across both global medical standards and local system conventions before it can reliably support care delivery, research, analytics, digital health platforms, and AI-driven applications. Our goal is not simply to make reports readable, but to help organizations that rely on clinical data build foundations that are consistent, interoperable, and ready for safe, large-scale use.

Medical data extraction is quick. Making it reliable is where real value is built.
Jonda Health Pte. Ltd.
1 NORTH BRIDGE ROAD
#19-09 HIGH STREET CENTRE
SINGAPORE (179094)
.png)
.jpg)
