Why we built JondaX

Making Health Data Usable for the Future of Healthcare
When we first started Jonda Health, I was not thinking about building a health data transformation engine. I was trying to solve something that felt much closer to home.
Over the years, I had seen from different angles just how difficult it was to work with health data in any meaningful way. I had seen it in clinical practice, I had seen it while working in pharma, and I had experienced it personally while managing multiple autoimmune conditions, which are thankfully now in remission. I also experienced it while supporting my brother-in-law through stage four pancreatic cancer. In each of these settings, the same issue kept showing up in different forms: the data existed, but it was often inaccessible, scattered, unstructured, inconsistent, or simply difficult to use when it mattered most.
On a personal level, this was not really about not understanding a single test result. It was more about how difficult it was to see the bigger picture of what was happening over time. My data sat across different providers in Singapore, with some records from the UK, while older records from South Africa were no longer accessible to me at all. Even within one country, the same biomarker could be labelled differently, shown in different units, and housed in different systems or applications. Some results were in portals, some in PDFs, some on paper, and some in places that were easy enough to access individually but very difficult to pull together into something coherent.
And the truth is, I did not sit there heroically entering everything into spreadsheets and trying to make sense of it all. I found it too laborious, and at times I simply did not have the energy for it. I think that is also an important part of this conversation, because when people talk about health data, they often forget what it feels like to be the person carrying the burden of it. If the data is hard to use, hard to compare, hard to trend, and hard to access, the burden quietly shifts back onto the patient, or onto the doctor, or onto whichever person in the system is willing to do the extra manual work.
That was a big part of why we first built Jonda, the app. The original intention was to create a way for people to collect, store, and manage their health data more easily across providers. It came from a very real need for something that could help make health data more usable at an individual level. One of the things that stood out for me personally was being able to look back at my own history in a more connected way. At one point, when I was feeling particularly tired, I was able to see that my iron-related biomarkers had been trending downward. That helped me act more quickly, speak to my GP, and get an iron infusion. It may sound like a small thing, but it made a real difference, and it showed me just how powerful it can be when health data is not only available, but actually usable.
At the same time, as we built Jonda, it became increasingly clear that the issue ran much deeper than creating a patient-facing application. What sat underneath was a much bigger infrastructure problem. The challenge was not only that people needed a better place to store their data. The challenge was that the data itself was arriving in so many different forms, structures, standards, languages, and levels of quality that making it usable at scale was a problem in its own right.
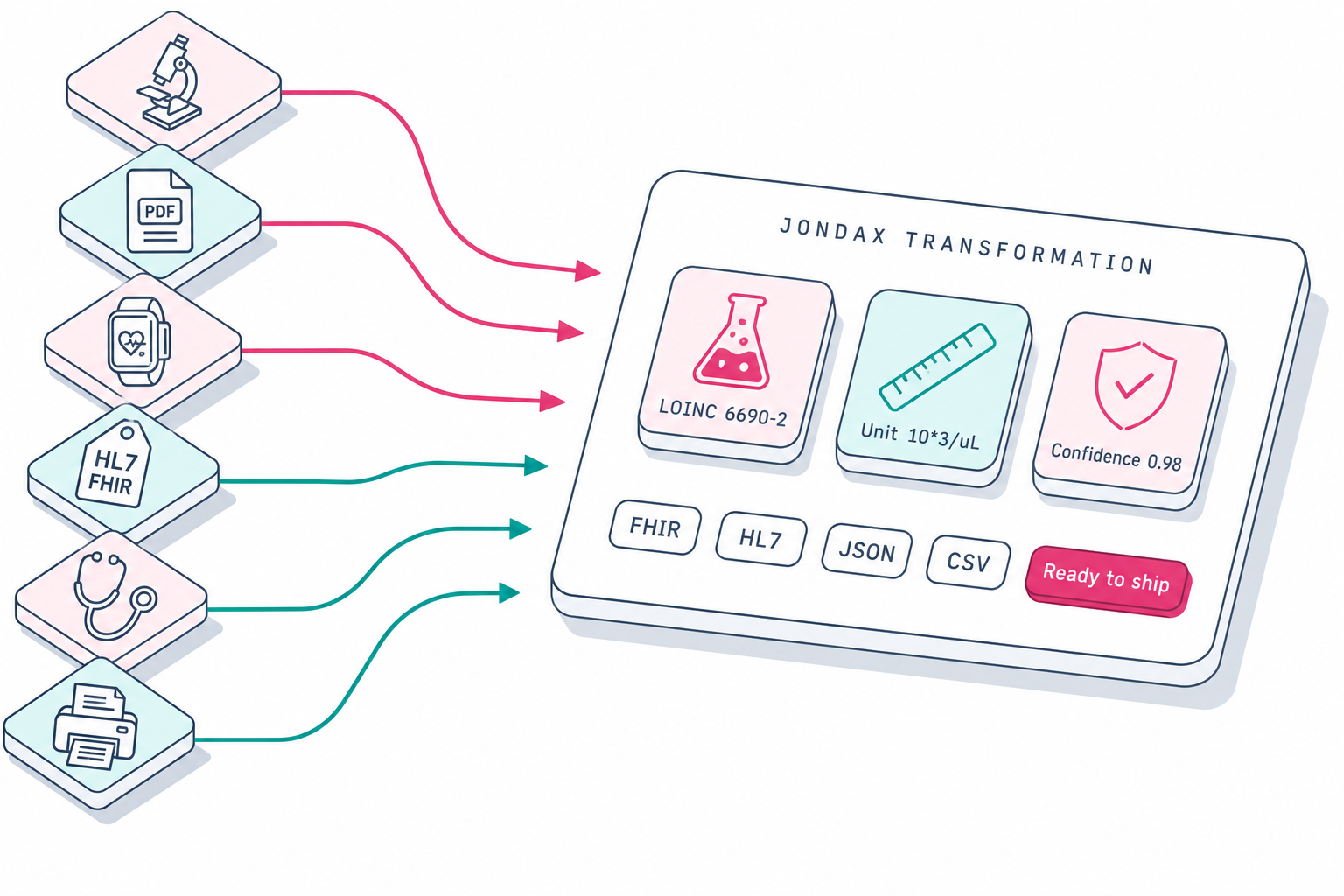
This became especially obvious as we worked more deeply with pathology and other clinical data. What looks simple on the surface is often anything but. A common biomarker can appear under multiple different names, with multiple different units of measure, and with reference ranges that vary depending on source, geography, instrumentation, or reporting style. Even something as seemingly straightforward as a white blood cell count can be represented in dozens of ways. Add to that PDFs, scanned reports, photos, CSVs, HL7 messages, FHIR resources, different decimal and comma conventions, multiple languages, and custom terminology, and the complexity grows very quickly. This is not an exception in healthcare. This is the reality of it.
That is really where JondaX came from.
JondaX is our health data transformation engine, built to help turn fragmented health data into data that is usable, structured, coded, and ready to flow into a format that client systems can actually work with. The goal has always been to create something flexible enough to work in the real world, not only in ideal conditions. Depending on the use case, that may mean structuring unstructured data, normalising files, translating content, converting units, mapping terminology, assigning codes, or preparing outputs so they can be received by another system in a meaningful way. Over time, this has evolved into a broader vision for JondaX as a universal health data transformation layer, accessible through a single API, that can handle different data types and different levels of complexity depending on what a healthcare platform or organisation actually needs.
For me, this is about much more than efficiency, although efficiency matters. It is also about what becomes possible when health data can finally be used properly. Better longitudinal visibility can support earlier diagnosis, more timely intervention, more holistic care, and a reduced burden on both patients and clinicians. I still think about one of my own diagnoses, which only became clearer because a doctor took the time to go back through older results one by one and look at what had been happening with my inflammatory markers over time. I remain deeply grateful for that level of care and attention, but I also remember thinking that this should not depend on a clinician manually opening each individual result and piecing the story together by hand. There is so much that can be surfaced earlier, and so much that can be made easier, if the underlying data is usable.
This is also where my own background has shaped how I think about the problem. Having grown up in South Africa, worked across different healthcare settings, and spent time in emerging markets, I care deeply about ensuring that the future of intelligent healthcare does not only work for the best-resourced systems. If we only build for environments where data is already clean, structured, standardised, and neatly integrated, then we will leave far too many people behind. Real healthcare is messier than that. Data still comes in PDFs, on paper, through scans, in different languages, and through systems that were never designed to work smoothly together. If we are serious about more intelligent healthcare, then that future has to be built with the real world in mind.
That is also why I care so much about making this easier for builders. Too many teams in healthcare are still spending enormous amounts of time and engineering effort solving the same foundational problems over and over again. They are building custom parsers, handling edge cases, trying to structure what is unstructured, and creating one-off pipelines just to get data into a state where it can power the thing they actually want to build. My view is that if more of that foundational layer is already solved, then healthtech teams can spend more of their time on the application layer, on care delivery, on patient experience, on workflows, on decision support, and on the kinds of products that can genuinely move healthcare forward.
Today, Jonda Health is a Singapore-based company with a team operating across Singapore, India, the Philippines, Thailand, and Switzerland. JondaX has processed more than 13 million data points across more than 10 languages, and we continue to build toward a future where health data becomes more usable, interoperable, and AI-ready. We are supported by AWS and Google for Startups, and we have launched a free tier for JondaX because we want it to be easier for people to start building with it, testing it, and seeing what becomes possible when the data layer is no longer the thing that slows everything down.
When I think about why we built JondaX, it comes back to something quite simple. There is so much potential in healthcare today, whether we are talking about earlier intervention, better decision-making, more personalised care, stronger research, or the possibilities emerging through AI. But so much of that potential still rests on data that is not yet usable enough for the future we are trying to create. JondaX exists because we decided not to sidestep that problem. We decided to take it on.
And for me, that has never only been about technology. It has been about building toward a world where health data can actually support better care, where the burden on patients is lighter, where clinicians and builders are better supported, and where intelligent healthcare does not become something reserved for only the most connected and well-resourced parts of the world.








