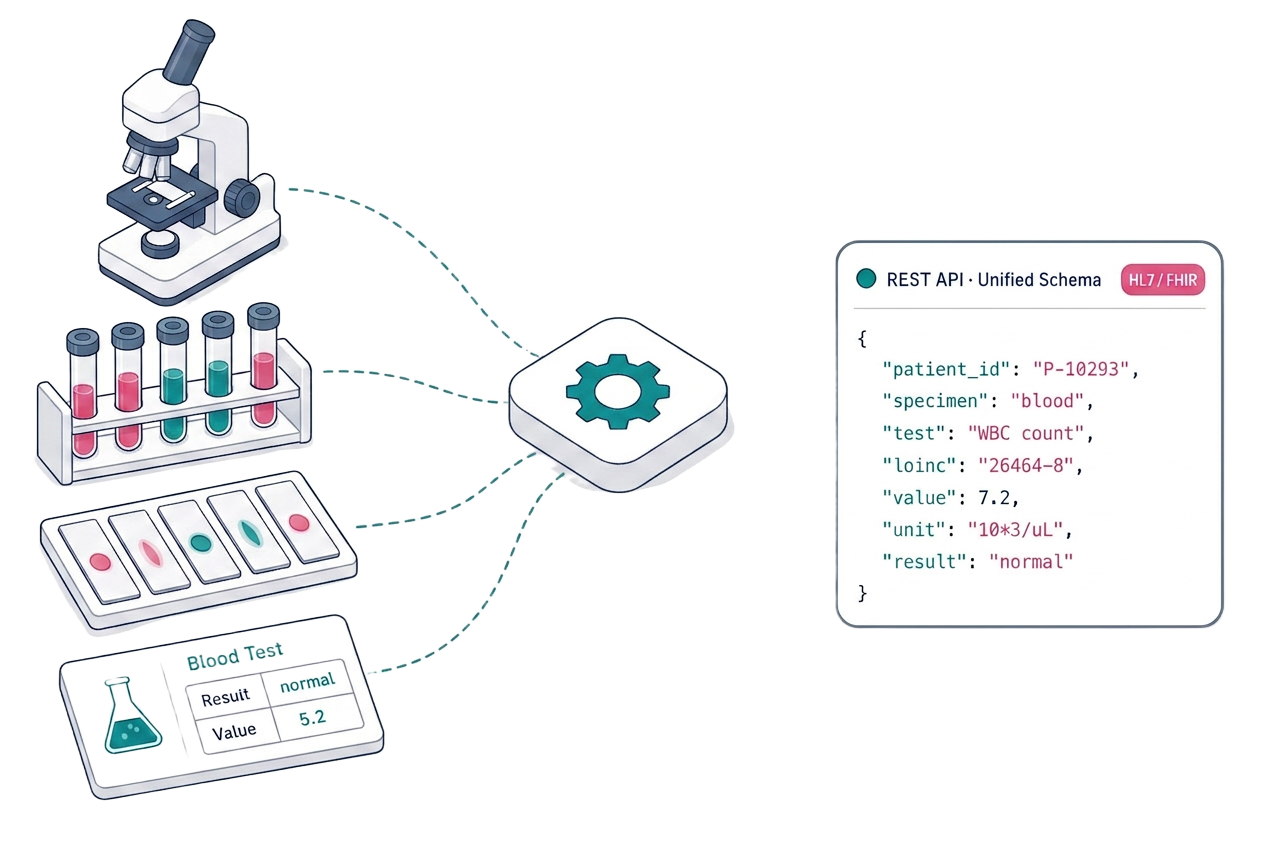
JondaX Pathology handles the full range of clinical laboratory specimens, not just standard blood panels.
Blood and haematology
From full blood count, metabolic, lipid, liver, and kidney panels to hormones, vitamins, tumour markers, inflammatory markers, cardiovascular markers, and less common blood-based biomarkers.
Urine analysis
Urinalysis, urine culture, spot and 24-hour collections, dipstick results, microscopy findings, and quantitative urine measurements.
Stool and faecal samples
Faecal occult blood, stool culture, parasitology, calprotectin, H. pylori antigen, and other gastrointestinal markers reported in lab results.
CSF and specialist fluids
CSF cell count, protein, glucose, culture, and other specialist markers reported in structured or semi-structured laboratory reports.
Sputum and respiratory specimens
Sputum cultures, respiratory pathogen panels, AFB smears, microbiology findings, and related laboratory results from respiratory specimens.
Microbiology and culture
Blood cultures, wound swabs, sensitivity results, antibiogram data, organism identification, and culture results from different specimen sources.
Other pathology reports
JondaX can support additional pathology report types depending on format, structure, language, terminology, and output requirements.